Privacy-Preserving, Robust, and Explainable Federated Learning Framework for Healthcare System
Project Summary
The success of many deployed machine learning (ML) systems crucially hinges on the availability of high-quality data. However, a single entity might not own all the data it needs to train the ML model it wants; instead, valuable data examples or features might be scattered in different organizations or entities. For example, medical images (CT and MRI) sit in data silos, and privacy concerns limit data sharing for ML tasks. Consequently, large amounts and diverse medical images from different hospitals are not fully exploited by ML. Distributed learning schemes such as federated learning (FL) (Konevc, 2016) provide a training scheme that focuses on training a single ML model using all the data available in a cooperative way without moving the training data across the organizational or personal boundaries. Given the wide applications of FL, guaranteeing that such a cooperative learning process is trustworthy is critical. In this proposal, we focus on three goals to design a trustworthy FL framework for the healthcare system with theoretical guarantees for its privacy, robustness, and agent-level data valuation and explainability, aiming to make the healthcare systems more efficient and trustworthy.
I. Background and Goals
There is a proliferation of AI-assisted medical devices and services in the healthcare industry to help clinicians make automated diagnosis, preliminary diagnosis, and patient data analytics (Iqbal, 2016). Training ML models for healthcare applications is, however, a daunting task. The conventional approach has been a centralized over-the-cloud ecosystem, in which the data is pooled from edge devices to the cloud, then annotated with the help of experts, and finally used for training large models. This approach, while being very effective so far, has several barriers. As the number of edge devices grow rapidly, data collection, pooling, and annotation become substantially resource-heavy. Centralized approaches would also evolve slowly to adapt to new datasets and domains. Finally, much of the collected on-device data are sensitive and private, so pooling and bringing them to the cloud poses privacy, security, and regulatory risks. There are two unmet challenges for ML-based healthcare system:
- Large-scale implementation and wide clinical adoption of ML-based healthcare systems are still not established. The ML models often do not translate well outside the settings of the model developed during the research phase. Specifically, ML models are trained and evaluated on a limited amount of data. This problem has been observed most notably when COVID-19 research used the same publicly available dataset containing confounding patterns. Currently, a substantial amount of medical data is collected decentralized across many hospitals that have not been used for ML training due to regulatory restrictions (e.g., GDPR and HIPAA) and privacy concerns.
- New urgency for data availability and utilization of health data. While continuing to fight the COVID-19 pandemic, the healthcare industry is drawing invaluable lessons to seek for better collaboration across the healthcare ecosystem to drive better outcomes, improve efficiencies and prepare for the next disruption (IBM, 2021). In particular, the COVID-19 pandemic shows limitations of data-sharing infrastructure in the existing healthcare systems. Therefore, this new sense of urgency and data demand is essential for possible collaboration between international healthcare infrastructures and governments worldwide.
FL (McMahan, 2017, Kairouz, 2021) is surging as a promising framework to address the above challenges by enabling decentralized ML across many edge users. The key idea is to keep users’ data on their devices and train local models at each edge user. The locally trained models would be aggregated via a server to update a global model, which is then pushed back to users. This approach promises to avoid the above challenges of data collection/pooling, slow adaptation to new conditions, and data privacy and security concerns.
Despite significant recent milestones in FL, there are several fundamental challenges that yet need to be addressed in order to enable its promise. First, edge users often have substantial constraints on their resources (e.g., memory, compute, communication, and energy), which severely limits their capability of training large models locally. Second, there is a large amount of system and data heterogeneity across edge users, which will make their ML objectives and capabilities vastly different. Third, as we make the ML/AI ecosystem decentralized across edge users, there is potential for more advanced security and privacy breaches into the FL system. Fourth, there is a lack of challenging, yet realistic, benchmarks and prototype systems for studying and experimenting FL designs, especially for resource-constrained edge users.
The overarching goal of this project is to address the above challenges and thus enable scalable and secure FL systems in practice. More specifically, this project will be centered around three critical questions/challenges: (1) how to provide strong privacy guarantees for users in the trained federated learning system? (2) how to ensure robustness against potential poisoning attacks? (3) how to evaluate contributions of participants. In particular, the proposed trustworthy FL framework is applicable to different FL mechanisms, including both horizontal FL (i.e., HFL where the data samples are distributed) and vertical FL (i.e., VFL where the features of data samples are distributed). Concretely, we propose (1) a sparsified differentially private (DP) data generative model to allow each local agent to generate data for scalable FL training; (2) the first certifiably robust training approach for FL against poisoning attacks via functional smoothing; (3) an efficient data importance/influence computation algorithm to identify “important” local agents for quantitative explainability via a near-optimal Shapley value computation. Specifically, the research scopes in this project are summarized as follows:
- Privacy-Preserving Sparsified Generative Model in FL. To propose a novel algorithm for aggregating high-dimensional gradients via compression and aggregation, combined with the PATE framework (Papernot, 2018), which consists of an ensemble of teacher discriminators and a student generator. We will leverage the conditional GAN as a backbone. The DP gradient aggregation algorithm is crucial for privacy and utility. To achieve high utility, the algorithm needs to preserve the true gradient directions of the teacher models. On the other hand, privacy composition for high-dimensional gradients often consumes a high privacy budget, resulting in a weaker privacy guarantee. To address this problem, we propose a novel compression algorithm for high-dimensional gradients and will provide novel element-wise SGD convergence analysis.
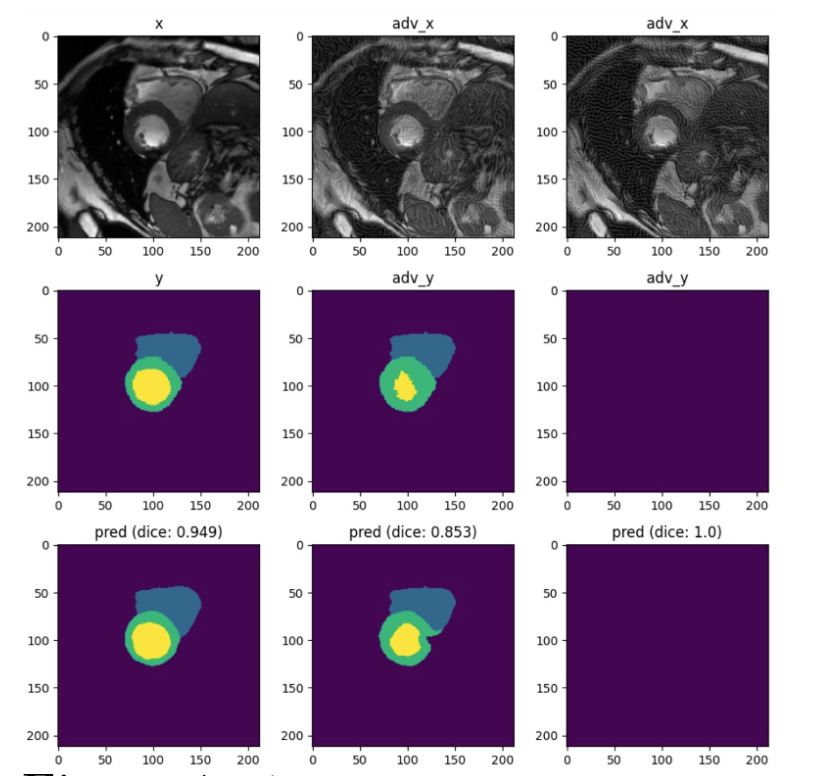
- Certifiably Robust FL against Poisoning (Backdoor) Attacks. We propose to achieve such certification via a novel functional smoothing training algorithm. In particular, different from existing work (Cohen, 2019), which only provides certification against evasion attacks by smoothing test samples, our proposed model will also be robust against training-time attacks. Specifically, based on the DP FL framework we designed above, we will first leverage the DP mechanism to guarantee the local model smoothness for free. We will then add noise to the global model’s parameters during every aggregation to perform parameter smoothing. Note that here we aim to defend against general backdoor attacks, and we will also empirically test our framework against different types of backdoors. For instance, as shown in Figure 1, the second row shows the adversarial targets and third row shows that after adding small optimized noise to the MRI images, the segmentation results are exactly misled to output a “thinner ring” or “nothing” given MRI inputs, which could lead to severe consequence in real medical deployment of AI techniques and we aim to address it in our proposed framework.
- Explainable Federated Participant Valuation in FL. After training the privacy-preserving and certifiably robust FL model, one may wonder why the accuracy, fairness, robustness, or other evaluation metrics are low/high. In practice, we may also be interested in finding the causal sources that lead to a specific model property, i.e., which agent or instance mostly likely contributes to the low accuracy? One way to solve this credit-assignment problem is by computing the Shapley value of this cooperative game. Here we propose to efficiently compute the Shapley value for each agent.
- Development of image-based disease detection and diagnosis application. To evaluate the practicality of the framework, we will develop a medical application focusing on image-based disease detection and diagnosis such as cancer, bone fracture, and etc. The application consists of three tasks: detection (localization of objects of interest in radiographs), characterization (capturing the segmentation, diagnosis, and staging of tumors), and monitoring of tumors (tumor changes).
II. Broader Impacts of this Proposal:
The research program itself will open up an efficient, elective and trustworthy federated learning platform integrated with diverse AWS ML services, and novel modeling and algorithmic opportunities within various intelligent applications, potentially changing the way the respective communities think, use, and design FL systems. The large-scale trustworthy FL platform will also contain various attack and defense methods for evaluation, which will significantly benefit the broader research community and promote AWS machine learning tools. The proposed new techniques will facilitate new methods of protecting data and critical learning infrastructure, an issue of immediate interest to government and healthcare industry. Moreover, such advancements have the potential for wide-ranging commercial and social impact, as they can be applied in a variety of domains to prevent potential privacy and security attacks, as well as providing explainability for data and agents based on their quantitative contribution.
These proposed techniques and analysis will significantly improve the trustworthiness and flexibility of AWS AI services.
This project has the following potential impacts on the wellness and health of people all over the world:
- A successful implementation of our FL framework could hold a significant potential for enabling ML-based healthcare systems at large scale, leading to models that yield unbiased decisions, and are sensitive to rare or new diseases while respecting governance and privacy concerns.
- Our framework has the potential to promote collaboration across the healthcare ecosystem with high privacy protection and security guarantee. It allows rapid sharing and dissemination of data between international healthcare infrastructures and governments worldwide.
- To advance the health of people and communities by finding new efficiencies in diagnosing, monitoring and treating disease.
III. Our Research Plan:
If awarded, we plan to jointly recruit and advise five Ph.D. students and one postdoc starting from Academic Year 2022. The research topic for each Ph.D. student will be based on the project scopes identified in Section I. The PIs from both institutions will collaborate together and lead a specific scope in this project. Our research plan is outlined as follows:
- In UIUC, we will design and develop the differentially private and efficient FL training framework, in which each agent would first train a DP local generative model based on their partial data/features, and then perform the proposed efficient aggregation. We will realize this framework on both image dataset (e.g., CIFAR-10) and credit score dataset. [one student – scope 1]
- In UIUC and VinUni, we will develop the certifiably robust FL framework against backdoor attacks, together with theoretical analysis for the certified bound of the trained global model, as well as the analysis on smoothing the training with different noise distributions and the corresponding convergence. To our best knowledge, this would be the first work to provide certifiable robustness against diverse backdoor attacks. [two students – scope 2]
- In UIUC and VinUni, we will develop the efficient Shapley value computation algorithm for both HFL and VFL settings, and evaluate the agent contribution given different prediction accuracy, robustness, fairness, and other model evaluation metrics. [one student – scope 3]
- In VinUni, we will develop an image-based disease detection and diagnosis application to evaluate the FL framework in this project on the collected medical images. [one student – scope 4]
We invite Dr. Stephen Schiffer (CHS faculty at VinUni) to serve as co-PI in this project to close the gap between technical skills and medical knowledge. Dr. Stephen Schiffer, who has extensive experience dealing with medical images, will help evaluate how the proposed framework could be applied to current healthcare systems. Also, we will form a medical expert team that consists of practitioners from the radiology department in Bach Mai Hospital and others. Co-PI Dr. Dam Thuy Trang and Dr. Luu Hong Nhung will help form the medical expert team for data collection and inputs on medical knowledge such as disease-specific patterns, disease classification labels, and interpretation of medical images. The PI from VinUni will work with the medical expert team to anonymize the collected dataset before using them in the project.
The $20K fund will be mainly used at the home institution to buy necessary equipment and computational resources (GPU, computer, and cloud services). When the student visits the host institution, the $20K fund will be used for conference expenses (travel and registration), clinical data collection expenses (at hospitals), and seed funding for obtaining external funding.
IV. Expected Outcomes:
High-quality Ph.D. thesis from the students co-supervised by both PIs.
- We will publish corresponding research papers for the above goals, and evaluate our proposed framework with different types of medical datasets.
- Software artifacts will be made available publicly open-sourcing and integrated with AWS AI and ML services such as Amazon SageMaker, and methodologies derived from these efforts will be integrated into coursework at UIUC and VinUni.
- New research problems found in this project will be used to apply for external fundings (VinIF and Nafosted in Vietnam or NSF in the USA).
- Support enthusiastic Vietnamese researcher (postdoc) at his/her early academic development stages throughout the project.
- Undergraduate and master students working on this project will primarily gain knowledge in information security, federated learning, data privacy, data analytics, and their applications.
- Train the medical doctors at local hospitals and CHS students toward the awareness of data privacy and adversarial attacks in the existing healthcare system.