Autonomous and Knowledge-guided Health Misinformation Defender Platform
Project Summary
Public health communication plays a crucial role in promoting health awareness and sustainable healthcare systems. However, falsehood, or misinformation, in healthcare is a pressing issue in modern society, as it arouses a mixture of anger, distrust, confusion, and anxiety that damage our daily life judgments and public policy decisions. Health disinformation and misinformation also cause financial harm to the public health systems around the world; for instance, in the United States alone, the monetary cost of COVID-19-related misinformation costs up to one billion dollars a day [1]. Due to the rapid advancement of media manipulation technologies in recent years, traditional statistical detection methods are becoming insufficient for identifying falsified or misrepresented media assets, which is reflected by the abundant untrue and harmful content that propagated during the COVID-19 pandemic. In some instances, it can be highly dangerous to use a medicine for the prevention or treatment of COVID-19 that has not been approved by or has not received emergency use authorization from the FDA. For example, there was a sudden shortage of an important medication for horses named Ivermectin because a growing number of people are taking it to treat themselves for COVID-19. In some countries such as Vietnam, the lack of fact-checking resources, combined with a low health literacy in the general public, further amplify and propagate disinformation.
In this project, we propose to develop Health Misinformation Defender (HMD), a highly advanced, scalable and fully automated platform that will ingest and assess cross-lingual and health-related news article, social media posts, technical documents, and other media types across a range of cultures, and prioritize the media items containing disinformation with malicious intent. The proposed effort prioritize those media content with high levels of malicious disinformation to assist public health analysts and policy makers to devise appropriate countermeasures to disinformation campaigns and the sources behind them much earlier, more accurately, and more broadly than ever before.
We believe that the development and deployment of HMD is crucial to improve (i) the public trust in healthcare organizations and their public health policies, leading to more effective governance and (ii) public health awareness and correspondingly health literacy of public citizens to allow them play active roles in improving their own health, engage successfully with community action for health, and push governments to meet their responsibilities in health and health equity.
I. Problem Motivation
A notable bottleneck of applying existing misinformation detection approaches for health-related media content is their portability to emerging events and low-resource training data settings. Furthermore, fact-checking health information is challenging and requires extensive biomedical and healthcare knowledge, which exists in an abundance amount of health scientific articles and healthcare assets (e.g., clinical notes), respectively. Specifically, existing detection approaches fail to combat health misinformation because of the following challenges.
- Challenge 1 (Multi-modal Content): The first challenge in constructing the platform is to extract semantic information and represent knowledge from the health-related media content, which comprises of multi-modal data such as text, image, audio, and video. Each modality might have only a portion of the overall narrative. Semantic data extraction failures can generate spurious inconsistencies within and across modalities. Existing approaches focus on single modalities [4,11] and cannot distinguish disinformation from innocuous inconsistencies between modalities.
- Challenge 2 (Rapidly Evolving Content): Harmful health content can evolve rapidly, triggered by relatively new events which can gain extensive media coverage within a short time span. For instances, COVID-19 misinformation spreads faster than the virus itself during the COVID-19 pandemic1 . Hence, misinformation detection in such scenarios requires systems that are able to adapt quickly, by working well under zero-shot or few-shot settings.
- Challenge 3 (Low-resource Training Data): Most fact-verification approaches focus on claims made in English only due to the data scarcity issue in other languages. The lack of fact-verification data in low-resource languages calls for an effective cross-lingual transfer technique for fact-verification. Additionally, trustworthy information presented in different languages can be complementary and helpful in verifying facts.
- Challenge 4 (Biomedical and Scientific Background Knowledge): Sophisticated disinformation campaigns often include fallacies, where the articles are self-consistent and contain the same falsehoods. While such falsehood in news articles from trusted sources can be verified by qualified healthcare and scientific experts, the verification process is time-consuming and expensive to perform on other content types such as social media posts. A seamless integration of knowledge from the biomedical scientific literature is necessary to improve the performance of the automatic verification process. However, biomedical terms are rare and cannot be learned well by only language models. We need to integrate knowledge from multiple data modalities to represent these entities, such as the molecule graph structures, natural language description in literature, natural language defintion and structured properties in the external database. Second, scientific papers are written for scientists, so they are often full of unexplained concepts. We need to construct an “extra brain” for our paper reading algorithms through entity linking to external databases. Third, the sentence structures in literature are often complex, and thus we need to capture the wide context between entities, or between event triggers and entities. We need to compress these wide contexts using text-to-graph parsing techniques to tackle this challenge.
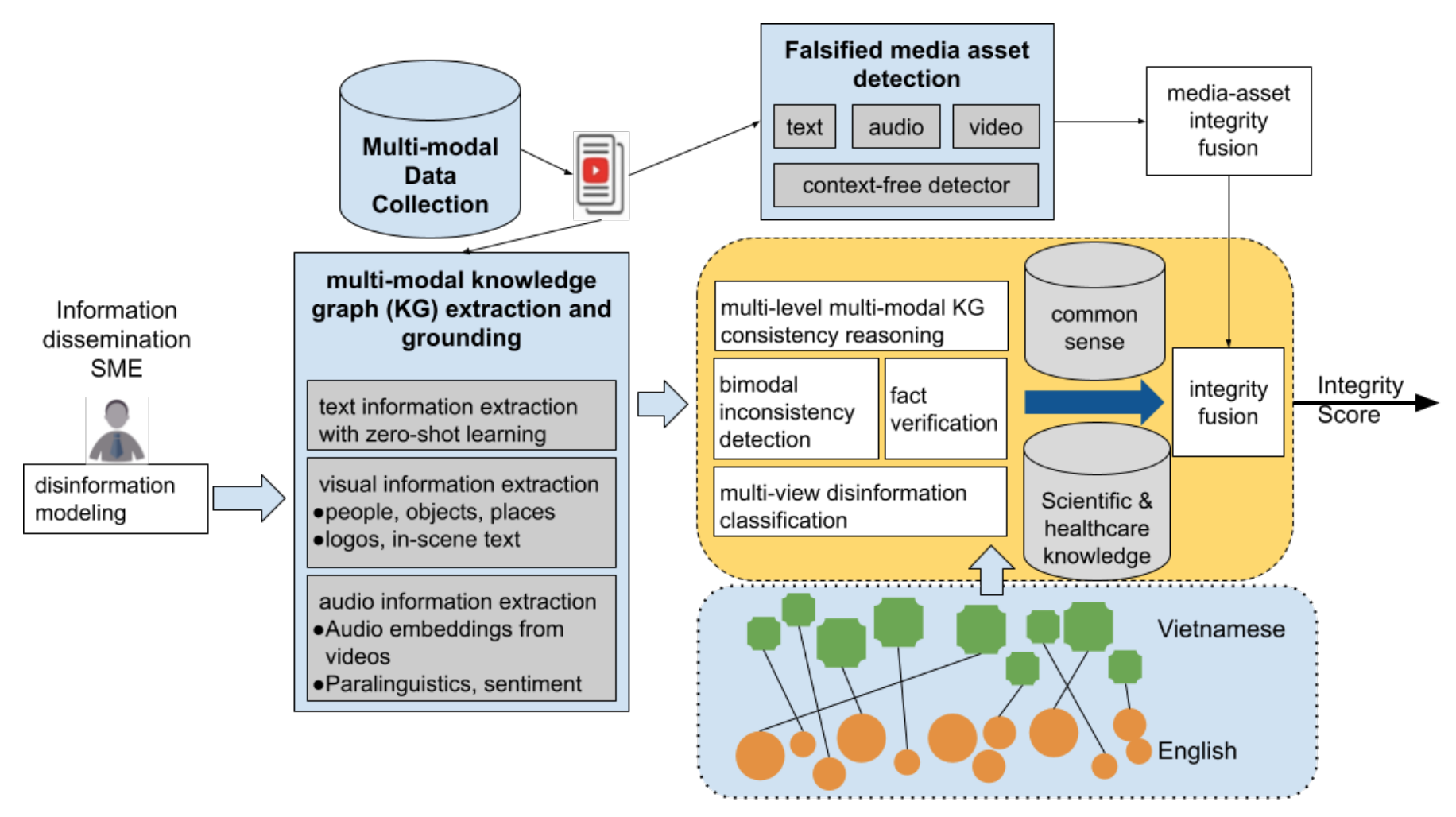
Figure 1: Health Misinformation Detection Platform
- Challenge 5 (Underutilized Healthcare Assets): Fact-verifying health-related news articles from biomedical scientific literature is necessary but is not sufficient since some biomedical scientific knowledge requires an extensive amount of time to be validated. Real-time production of biomedical and scientific articles (one notable example is the COVID-19 pandemic) contribute to the uncertainty of scientific knowledge. We need a different source of background knowledge for real-time fact verification. Healthcare assets such as clinical note and patient medical history, which can contain a large amount of real-time collected facts, can be used to improve the precision of the existing verification techniques.
II. Intellectual Merits and Research Objectives
The goal of this project is to develop a misinformation detection platform that can ingest a wide variety of large-scale health-related data including news and social media posts in multiple languages, including high-resource languages such as English and low-resource languages such as Vietnamese, then perform cross-lingual fact-checking of these assets against the background knowledge extracted from biomedical scientific literature and healthcare assets (Figure 1). The detailed research objectives are as follows:
Research Objective RS1: Multi-modal Knowledge Graph Extraction for Multi-modal Media Assets
Existing approaches focus on single modalities [4,11] and cannot distinguish disinformation from innocuous inconsistencies between modalities. HMD offers a comprehensive and flexible semantic consistency reasoning approach composed of three levels: intra-modal, inter-modal, and background consistency. Within and between these levels, our approach will differentiate disinformation from spurious missing, partial or inconsistent information through knowledge-graph label consistency [14,6,12], graph structure alignment, topic-shift detection [3,2], audio-visual consistency [7,8], weighted hypergraph reasoning and grounding [13,9].
HMD’s extraction and association methods focus on knowledge element level text for granularity and accuracy, speaker and style by using deep neural networks to detect differences in paralinguistic information, visual scene graph extraction for images, and multi-modal KG extraction for holistically detecting sentiment across MMA modalities. Extraction and association will output scores, but more critically will yield explanations of their results based on our explanation ontology. We will also develop additional auxiliary extraction and association methods necessary for the team’s development, and the program’s hackathons and transition needs.
Research Objective RS2: Few-shot Learning Models for Rapidly Evolving Content
Harmful health misinformation can evolve rapidly, triggered by relatively new events which can gain extensive media coverage within a short time span. Hence, misinformation detection in such scenarios requires systems that are able to adapt quickly, by working well under zero-shot or few-shot settings. In this project, we propose a fine-grained detection framework, instead of prompts as in previous work, that leverages zero-shot Question Answering (QA) using directed questions to solve a diverse set of sub-tasks such as topic filtering, misinformed object detection, and bad-actor identification. In this work, we will solve end-tasks by formulating them as directed questions that will be fed into a QA model, which will allow us to conduct rapid adaption to a new domain or a new scenario. We propose to formulate questions in a hierarchical way and obtain answers in an incremental way. For example, given a document, we will first ask questions like “What is being claimed?”, and if the answer is “The virus was manufactured by the United States.” then we further ask the question “Who said that virus was manufactured by the United States?” to extract the claimer as “Pro-Kremlin media”. Our preliminary results show that a QA model is able to outperform other attribution methods for bad-actor detection, which requires document-level reasoning.
Research Objective RS3: Cross-lingual Transfer Technique for Fact Verification
Most fact checking approaches focus on misinformation made in English only due to the data scarcity issue in other languages. The lack of fact-checking datasets in low-resource languages calls for an effective cross-lingual transfer technique for fact-checking. Additionally, trustworthy information presented in different languages can be complementary and helpful in verifying facts. We propose to develop the first retrieval-augmented fact-checking framework that aggregates evidence retrieved from multiple languages through a cross-lingual retriever. Given the absence of cross-lingual information retrieval datasets with claim-like queries, we will train the retriever with a self-supervised algorithm that creates training instances by translating the title of a passage, using the high-resource English language and the low-resource Vietnamese language as a case study. We will build on top of our previous pioneering work on Information Extraction for low-resource languages [14,6].
Research Objective RS4: Cross-lingual Fact Verification against Background Knowledge
To acquire solid background knowledge for fact-checking, we first propose to apply our state-of-the-art knowledge extraction techniques [12,3,2] to automatically construct knowledge bases from both scientific literature and healthcare assets.
- Background Knowledge from Biomedical Literature. The constructed knowledge bases of scientific literature include chemical entities and reactions between entities, and thus they can be used to mine evidence for biomedical facts. To tackle the challenges in Challenge 4, we aim to extend biomedical entity representation from reaction-aware molecule representation to knowledge-enhanced multimodal representation by constructing a shared common semantic space among multiple data modalities: (1) 2-D images of molecules, representing the underlying molecules or reactions; (2) text-based molecule descriptors; (3) chemical graph structure; (4) natural language definition and description in literature; and (5) structured properties in external databases. Our joint representation-based translator will allow an end-user with no knowledge of machine learning to generate a list of molecules according to their desired specifications. This has the potential to vastly improve the targeting of current molecule generation techniques and expand these tools to non-experts, allowing for significant improvements for creating new chemical techniques across a variety of industries. We will also enhance the performance of our end-to-end knowledge extraction framework by exploring a broader range of properties and information that can be extracted from external knowledge bases.
- Background Knowledge from Healthcare Assets. We propose to construct medical knowledge bases from medical records (collected by hospitals) as additional background knowledge to improve real-time responses against disinformation of emergence events. We first need to digitize hand-written/analog records into the corresponding electronic health and medical records (EHRs/EMRs). One approach is to utilize the developed visual recognition tools in VISHC’s VAIPE project to reduce data collection cost. Next, we propose to employ differential-privacy techniques developed in the VISHC’s Privacy Preserving Healthcare System project to anonymize the EHRs/EMRs. We then construct the knowledge bases linking medical conditions, diseases, and symptoms directly from EHRs/EMRs. A similar knowledge graph of medical conditions, disease and symptom relationships can be extracted. The extracted knowledge graph provides necessary semantic context for inconsistency reasoning to estimate disinformation of emerging events where real-time scientific knowledge cannot.
Research Objective RS5: Dataset Collection
We have collected COVID-19-related English news articles from Google News [5] and millions of scientific papers [10]. To support our work in RS3, we propose to collect corresponding COVID-19 datasets in Vietnamese, as the low-resource language in our project. World knowledge is a critical component to detecting disinformation, and we will also collect datasets from the biomedical scientific literature to construct the biomedical background knowledge databases as discussed in RS4. Finally, we will collaborate with the hospitals and collect both EHR and EMR, as discussed in RS4. We also considered the temporal aspect for collecting datasets. As the development of HMD matures, teams will need recent or even real-time news and social media feeds.
III. Broader Impact
We discuss the potential impacts of our project on the wellness and health of people all over the world:
- A successful deployment of our misinformation detection platform could improve the public trust in healthcare organizations, including both public and private organizations, and their public health policies, leading to more effective governance. Effective planning and governance will bring tangible impacts on citizens, patients, clinicians, and healthcare staff, and significantly reduce healthcare costs.
- Reducing health misinformation is equivalent to improving public health awareness and correspondingly increasing public health literacy. Individuals have opportunities to play active roles in improving their own health, engage successfully with community action for health, and push governments to meet their responsibilities in health and health equity.
- Finally, although the proposed methods (including both modeling and algorithmic artifacts) are primarily discussed in the context of the healthcare domain, they will be applicable to various other areas, such as science, politics, terrorism, science, entertainment and natural disasters where detecting misinformation is critical.
IV. Research Plan
We plan to recruit and collaboratively advise five Ph.D. students and one Postdoc starting from Academic Year 2023. The research topic for each Ph.D. student will be based on the research objectives identified in Section II. The PIs from both VinUni and UIUC will collaborate and lead a specific scope in this project, as follows:
- In UIUC and VinUni, we will design and develop the multi-modal knowledge graph extraction framework of data from multi-modalities, including text, video, image and speech [one student – RS1]
- In UIUC, we will develop the Few-shot Learning Models that are capable of detecting misinformation in rapidly evolving content [one student – RS2]
- In VinUni, we will develop the cross-lingual transfer techniques that involve high-resource English language and low-resource Vietnamese language [one student – RS3]
- In UIUC and VinUni, we will collaboratively design and develop cross-lingual fact verification techniques against Background Knowledge from biomedical scientific records and EHR/EMR collected from hospitals, [two students – RS4]
- In VinUni and UIUC, we will collect the corresponding datasets to support each individual research objective, as discussed in RS5.
The $20K fund will be mainly used at the home institution to buy necessary equipment and computational resources (GPU, Servers, and Cloud-computing Services) and to collect additional dataset (at hospitals) needed in each scope. When the student visit the host institution, the $20K fund will be used for conference expenses (travel and registration), additional data collection expenses (at hospitals), and seed expenses for obtaining external funding.
V. Expected Outcomes
In this project, we expect the following outcomes:
- High-quality Ph.D. thesis from students co-advised by both PIs.
- Published research papers for the above goals to top-tiered conferences and journals in Health Science (HS), Machine Learning (ML), Data Mining (DM), Natural Language Processing (NLP), and Computer Vision (CV).
- Data and Software artifacts that are made open-sourced and publicly available to public health organizations and policymakers.
- All quarterly status reports, final reports, presentations at the kickoff, PI, and other meetings, user manuals, and a detailed software design document besides technical papers.
- Methodologies derived from these efforts will be integrated into coursework in HS, NLP, CV, DM, ML, Software Engineering, etc… at UIUC and VinUni.
- New research problems that will be used to apply for external fundings (e.g., VinIF/Nafosted in Vietnam or NSF/NIH/DARPA in the US).
- Support for Vietnamese postdocs at his/her early academic development stages during the project.
- Valuable technical/research knowledge/skills in HS, ML, CV, NLP, DM, etc… of undergraduate and master students.
- Awareness of the significance of misinformation and disinformation from researchers, experts (e.g., medical doctors), CHS/CECS/CBM/CAS students, public citizens, and policymakers.
Team Members and Qualification
PIs: Heng Ji, CS faculty, UIUC | Khoa D. Doan, CS faculty, VinUni. Co-PIs: Wray Buntine, CS faculty, VinUni | Hieu H. Pham, CS faculty, VinUni, | Andrew W. Taylor-Robinson, CHS faculty, VinUni | K. David Harrison, Linguistic faculty (CAS) VinUni | Bach Xuan Tran, Department of Health Economics faculty, Hanoi Medical University
Qualification: We have assembled a team of researchers and experts on information extraction (Heng Ji, Khoa D. Doan), Natural Language Processing/Linguistics (Heng Ji, Wray Buntine, K. David Harrison), Computer Vision (Khoa D. Doan, Hieu Pham), misinformation studies from both the computational domain (Heng Ji) and public health domain (Bach Xuan Tran, Andrew W. Taylor-Robinson), machine learning/AI (Heng Ji, Khoa D. Doan, Wray Buntine, Hieu Pham), and public health research (Hieu Pham, Andrew W. Taylor-Robinson, Bach Xuan Tran). We believe the extensive experiences and broad perspectives in the relevant domains of the members create a unique and effective interdisciplinary collaboration for the success of combating health misinformation:
- Heng Ji is a Professor in the CS Department at the UIUC. She is an expert on information extraction from unstructured data. She received the IEEE “AI’s 10 to Watch” Award (in 2013) for her work on extracting information from heterogeneous data, and served on multiple DoD-sponsored projects on knowledge extraction. Her team has developed a suite of state-of-the-art knowledge extraction systems for multiple data modalities and 300 languages. These technologies have consistently achieved top performance in international research evaluations at NIST SM-KBP, LoreHLT, and TAC-KBP and ACE, and won the ACL2020 Best Demo Paper Award and NAACL2021 Best Demo Paper Award. She has been invited to give many keynote speeches and conference tutorials, including KDD2022’s tutorial on misinformation detection. Google Scholar
- Khoa D. Doan is an Assistant Professor in the College of Engineering and Computer Science at VinUni. He has extensively researched practical retrieval methods and generative modeling in several domains such as image, text, and graphs. He has extensive industry and research experience in adversarial algorithms and generative models that generate synthetic data to im-prove zero-shot and few-shot learning. He has first-authored several published works at top ML/CV/DM and Information Retrieval conferences such as NeurIPS, ICCV, CVPR, WWW, CIKM and SIGIR. He has led or collaborate with multiple industry teams and startups in developing high-performance and data-intensive, distributed machine learning applications in advertising (Baidu/Criteo), e-commerce (Baidu), and science (NASA). He serves as Program Committees in top ML/DM/CV conferences such as NeurIPS, ICLR, ICCV, ECCV, AAAI, ICML, and CVPR. He was a recipient of the NSF Urban Computing Fellowship in 2016. Google Scholar
- Wray Buntine is a Professor in the College of Engineering and Computer Science at VinUni and Director, Computer Science Pro-gram. His research interests include probabilistic and Bayesian methods for machine learning, particular document analysis and natural language processing. His publications span information retrieval and semantic search, document summarisation, knowl-edge graphs, translation and language models. He has taken senior reviewing and editing positions on most major conferences and journals in machine learning and natural language processing. Google Scholar
- Hieu H. Pham is an Assistant Professor in the College of Engineering and Computer Science at VinUni. His research interests include Computer Vision, Multimodel Machine Learning, Medical Image Analysis, and their applications in Smart Healthcare. He led several large-scale AI projects to develop new AI solutions for medical data analysis. He is the author and co-author of 30 scientific articles that appeared in about 20 conferences and journals, such as Scientific Data (Nature), CV and Image Understand-ing, Neurocomputing, Nature Scientific Data, MICCAI, MIDL, ICCV, and ACCV. He got a DAAD Fellowship for Outstanding Young Researcher in AI and Medicine in 2021 and won AI Awards in 2022. Google Scholar
- Andrew Taylor-Robinson is Professor of Microbiology & Infectious Diseases in the College of Health Sciences at VinUni, and an International Scholar of the Center for Global Health, Perelman School of Medicine, University of Pennsylvania. Andrew has 35 years’ experience of health sciences research, primarily in the areas of infectious diseases immunology and epidemiology, antimicrobial resistance and stewardship, and public health engagement and communication. His work is increasingly focused on addressing issues relating to global health challenges and health inequities that affect vulnerable populations at local and regional levels. This includes public health literacy, for example in relation to the (mis)use of antibiotics. He collaborates on several interdisciplinary research projects in Asian and African low-middle income countries. He has authored over 300 peer-reviewed journal papers and book chapters, and is on the editorial board of leading Q1 health sciences journals. Google Scholar
- K. David Harrison is a Professor in Vinuni’s College of Arts and Sciences and Vice Provost for Academic Affairs. His research in Linguistics and Anthropology explores environmental intelligence in ethnic minority languages of Vietnam and other locations. He created the Talking Dictionary platform which provides community-sourced digital lexicography for over 200 low-resource languages. Google Scholar.
- Bach Xuan Tran is a Health Economist whose research focuses in Global Health Policy, Health Services and System, and e-health. He is an Associate Professor at Hanoi Medical University and Johns Hopkins University. He has extensive experience in consulting for the World Bank, WHO, UNAIDS, UNDP, UNICEF, and international organizations (e.g., FHI 360, Abt Associates, ACCESS Health Int . . . ) and governments on global health and development issues in South-East Asia. These consulting works involve determining cost-effective interventions, assessing health services and innovations, and strengthening health systems in the region. Since 2015, he is co-chair of the Global Health Innovations Network (GHIN) which aims to fostering innovations, research and publications towards sustainable health and development in LMICs. Recently, he is part of a global network that focuses on combating infodemic. Google Scholar
Future Extensions and Sustained Collaboration
This project opens our UIUC-VinUni collaborations in combating misinformation in public health in the near term and other do-mains in the long term. For research in health misinformation, the collaboration will prepare us to obtain larger, external grants such as VinIF (Vietnam), NAFOSTED (Vietnam), NIH (United States/public-health misinformation), European Media and Information (Europe/disinformation in multidisciplines), Meta/International Fact-Checking Network (Industry/misinformation), Google (Industry/misinformation), etc… Several proposed components of our project through the interdisciplinary collaboration can be extended into other domains such as healthcare, medicine, applied materials, social media, and education, further increasing the impacts of the project. For example, the proposed multi-modal representation learning methods can be extended to other healthcare applications such as precision medicine. In another example, the proposed molecule representation learning can be extended into the drug or applied-material discovery domain.
Our team will work closely with public health professionals and policymakers all over the world to deploy our platform to combat health misinformation. We plan to conduct regular meetings for progress update (once every month) from both VinUni/UIUC members of the project, including PIs/Co-PIs, Postdocs, and Students. We plan to establish a VinUni/UIUC research seminar series (once every 2 weeks) where both VinUni/UIUC and external researchers and experts in misinformation and related fields are invited as speakers. Finally, we anticipate that the VinUni/UIUC researchers in this project will visit the other campus once a year for 2 weeks to further enhance our interdisciplinary collaboration.